Your Org Has the Same Scaling Problem as a Badly Tuned Training Run
AI raised individual throughput but coordination overhead stayed fixed. For many product-engineering orgs, the bottleneck flipped from compute-bound to communication-bound.
I scale LLM training for a living — eliminating communication overhead so compute actually computes. The same bottleneck is strangling most tech orgs, and they are looking in the wrong place.
The bottleneck moved
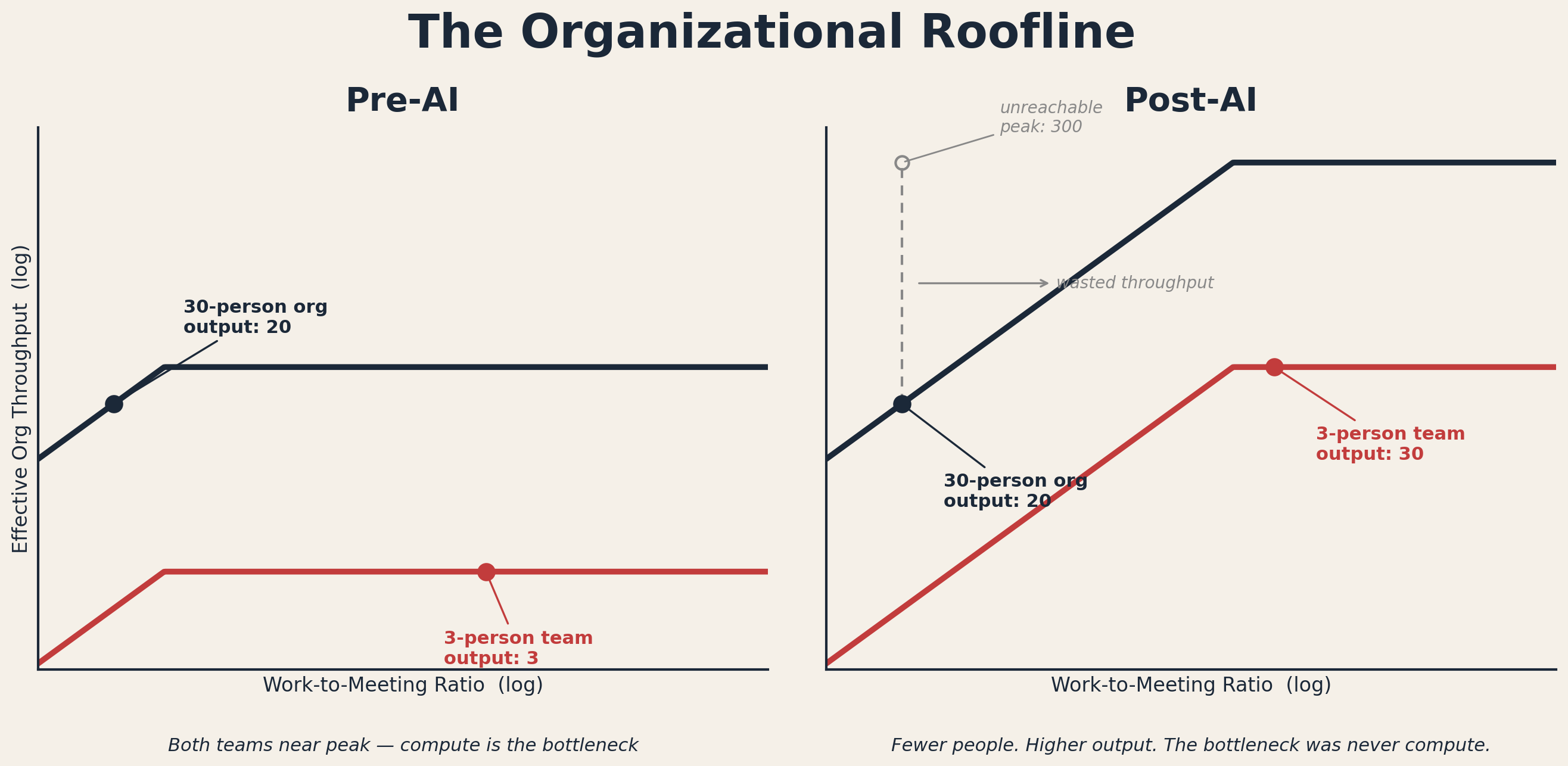
Every system hits one of two ceilings: the speed of individual work, or the overhead of coordination. This mirrors what performance engineers call the roofline model — your output is capped by whichever constraint binds first.
Pre-AI, orgs were compute-bound: individual output was the ceiling, so you hired more people and accepted the coordination cost. Post-AI, every individual got meaningfully faster on implementation tasks — controlled studies measure 20–55% on well-defined coding tasks, though gains shrink or reverse on complex codebases developers already know well — but even the conservative end shifts the binding constraint.
The interconnect did not speed up with them. Knowledge workers spend 57% of their time communicating and 43% creating; meeting time is up 252% since 2020, largely driven by remote work, but the coordination tax was bloated before AI sharpened the contrast. A longitudinal study of 22,000 developers confirms the pattern: individual task completion rose 21% with AI tools, but organizational delivery velocity was flat. PRs grew 154% larger and review time nearly doubled — the coordination pipeline did not just fail to speed up, it got heavier. DORA’s 2024 report shows the same at industry scale: positive individual sentiment, but delivery throughput flat-to-declining and stability meaningfully down.
Not all coordination is overhead — cross-team dependencies and shared-state services create irreducible coordination that no restructuring eliminates. But the ceremonial kind — status meetings, roadmap alignments, cross-team syncs that exist because the org chart demands them, not because the problem does — became the bottleneck. When Shopify deleted all recurring meetings of 3+ people as part of a broader restructuring, they recovered 322,000 hours in one month and completed 25% more projects, though disentangling the meeting effect from concurrent headcount changes is not straightforward.

The organizational roofline: each team’s output is capped by whichever ceiling binds first — individual speed or coordination overhead.
What “taste” actually means
The scarce resource shifted from execution to judgment — what I have been calling taste: knowing which 3 out of 10 directions will actually work, and being right most of the time. The person who spots that a coding agent quietly dropped a retry policy because they know which failures are transient is exercising taste. The person whose instinct is to schedule a sync before investigating is substituting process for judgment.
Two modes among tech managers. One cultivated that judgment — stayed close to the work, looks at an architecture and sees the failure mode five turns ahead. Give them AI tools and they become a one-person product team. Their taste compounds: they attract strong engineers, coach them into the same judgment, so the multiplier is team-wide.
The other spent years relaying context between teams — aligning stakeholders, scheduling syncs, tracking deadlines. AI automates the mechanical parts: status aggregation, timeline tracking, cross-team updates. What remains is the judgment work — navigating organizational politics, sequencing cross-team dependencies, making hard tradeoff calls — that was always embedded in the coordination but is now exposed as a distinct skill rather than bundled with the mechanical relay.
Most real managers are a blend. The question is which function dominates their calendar. The first mode gets amplified. The second gets automated.
The fix is not “managers should learn to code with AI”
The fix is structural. I have watched this in distributed training itself: a three-person kernel team — one architect, two engineers — shipped a communication backend in four months that a twelve-person team at a peer lab spent a year matching. The difference was not talent. The larger team had weekly syncs, a program manager, and a planning process that consumed a third of their engineering hours. The smaller team had a shared channel and a whiteboard. Amazon’s 2025 shareholder letter describes a similar pattern at larger scale: six engineers, building on AI coding agents, shipped a new inference engine for Bedrock in 76 days — work estimated at 40 people for a year, though shareholder letters present self-selected successes. For product work with a well-defined surface, small teams with taste capture the speed-up while large teams absorb it into coordination.
Some coordination work is genuinely valuable — shielding the team from politics, mentoring through career-defining moments, holding institutional memory. The question is whether that requires a dedicated relay role or becomes part of how the player-coach operates.
Middle management is the layer where every node exchanges information with every other node — what distributed systems call all-to-all — and whose cost grows quadratically with participant count. That is the layer you optimize away. That optimization has a human cost — careers built around coordination skills do not pivot overnight, and the transition will be painful for people whose expertise is real but newly redundant. VPs aggregate signal, allocate resources, and set direction — closer to a reduce than a relay. That role stays.
If your team does product work with a well-defined surface and your AI adoption push has not moved the needle, measure your work-to-meeting ratio. That is where the bottleneck moved.